SpendQube cleanses and enriches your spend data so your team has an accurate, structured and usable foundation for every procurement activity that follows.
Spend data arrives from multiple sources: ERPs, finance systems, purchase cards, subsidiary feeds, and rarely in a consistent format. Supplier names vary. Categories are missing or misapplied. Spend is buried in catch-all codes that tell you nothing useful.
The result is a dataset that looks complete on paper but cannot support reliable analysis, meaningful benchmarking or credible savings identification.
SpendQube combines intelligent data processing with procurement expertise to transform raw, messy spend data into a clean, enriched and properly categorised dataset; one that your procurement team can actually work with.
1. Data arrives from too many sources
Most organisations pull spend data from several systems; ERP outputs, accounts payable extracts, card programs, subsidiary feeds. Each source has its own format, coding conventions, and inconsistencies. Consolidating them without introducing further errors requires more than a spreadsheet.
2. Supplier records are inconsistent and duplicated
The same supplier often appears under multiple names, abbreviations, and trading entities. Without normalisation, it is impossible to understand true supplier spend, identify consolidation opportunities, or benchmark accurately.
3. Spend categorisation is incomplete or wrong
GL codes and cost centre mappings rarely reflect commercial categories. A large proportion of spend typically sits in miscellaneous or unclassified codes, making it invisible to procurement. Even where categories exist, they are often applied inconsistently across business units or time periods.
4. The problem compounds over time
Spend data quality degrades with every new system, acquisition or organisational change. Teams that relied on a clean dataset two years ago may now find it significantly less reliable, but without a structured cleansing process, the scale of the problem is hard to measure.
5. Internal resource is rarely available to fix it
Cleansing spend data properly is time-consuming. Most procurement teams do not have the bandwidth, tooling or categorisation expertise to work through large datasets systematically. The work either does not get done, or it gets done inconsistently by different people using different approaches.


SpendQube approaches data quality as a precondition for everything else in procurement. A clean, enriched dataset is not a nice-to-have, but the foundation for spend analysis, savings identification, supplier rationalization and category management.
We combine automated data processing with human categorization expertise to deliver a spend dataset that is accurate, structured and ready to use. Where AI-assisted categorization handles volume and consistency, our procurement specialists apply judgement to edge cases, complex categories and industry-specific spend.
We don’t just deliver a snapshot. We support continuous improvement.
Our managed service helps you prioritise opportunities, track progress and embed stronger spend governance, with procurement experts guiding you every step of the way.
SpendQube helps procurement teams move beyond unreliable data to build the spend visibility needed for confident, commercially credible decisions.
When your spend data is clean and consistently categorized, you can see what you are actually buying, from whom, and at what cost. That visibility is the starting point for every meaningful procurement activity.
Poor data quality slows down opportunity identification. A clean dataset allows your team to move quickly, spotting consolidation opportunities, benchmarking categories and building a savings pipeline without first spending weeks fixing the underlying numbers.
Procurement teams that present spend data with confidence carry more weight in commercial conversations. Clean, well-structured data supports business cases, category strategies and supplier negotiations with numbers that hold up to scrutiny.
A one-off cleansing exercise degrades quickly. SpendQube establishes a repeatable process that maintains data quality as new spend flows in, so your dataset stays accurate without requiring constant manual intervention.
Spend data cleansing is a structured process that moves from raw data consolidation through to an enriched, analysis-ready dataset. SpendQube manages each stage, combining platform capability with procurement expertise.
We ingest spend data from your source systems: ERP exports, AP extracts, card data and any other feeds. The data is deduplicated, normalized and cleansed to remove inconsistencies, resolve supplier name variations, and produce a single consolidated spend file. At this stage, the data is structurally sound and ready for classification.
Spend is classified against a consistent category hierarchy using a combination of AI-assisted categorization and procurement specialist review. Unclassified and miscategorized spend is reassigned to meaningful categories. Supplier records are enriched with intelligence such as, sector, size, risk indicators and market context, where relevant.
The cleansed and enriched dataset is delivered through the SpendQube platform, providing your team with accurate and structured spend visibility from day one. Ongoing data flows are configured so that new spend data is processed consistently, maintaining quality without additional manual effort.
Depending on your needs, we can provide ongoing managed support. Our procurement experts work alongside your team to help execute the initiatives you prioritise, ensuring savings are captured, compliance is maintained and supplier performance continues to improve over time.
A single, unified view of your organisation’s spend across all source systems, deduped and normalised, ready for analysis without further manual preparation.
A clear summary of where your data quality issues were concentrated, by source system, business unit or spend type, giving you a baseline and evidence of improvement.
Supplier records enhanced with relevant intelligence: sector classification, spend concentration and risk indicators to support supplier management and sourcing decisions.
A repeatable process configured within the SpendQube platform so that future spend data is processed consistently, maintaining data quality without requiring a manual exercise each time.
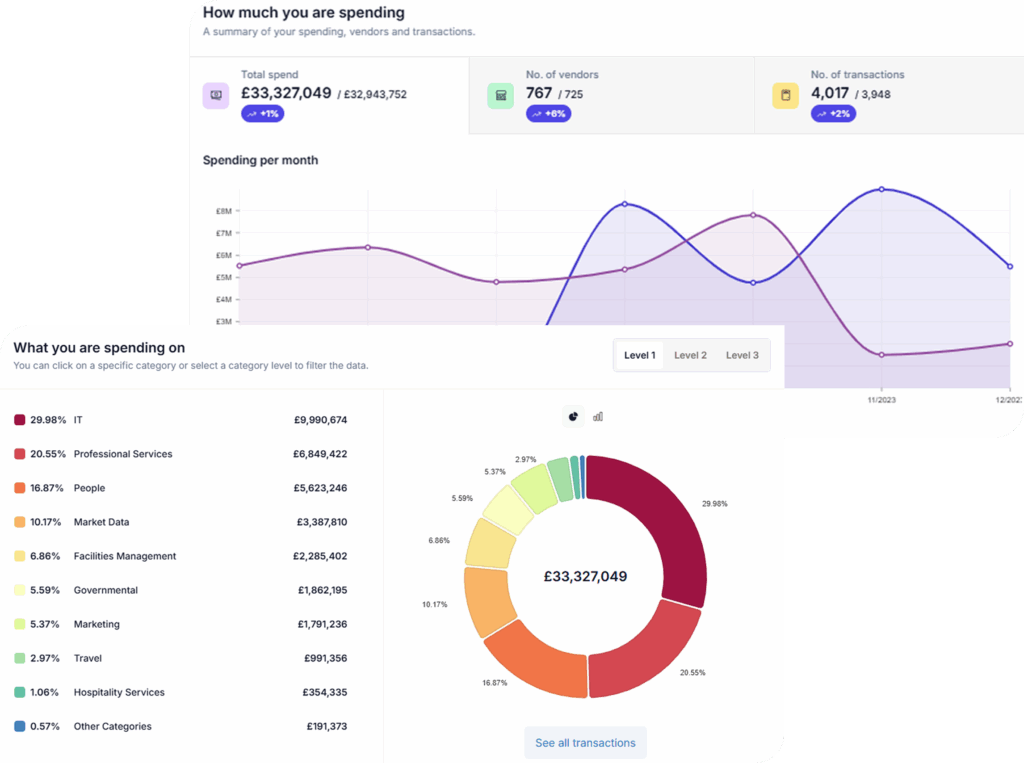
It is the process of taking raw spend data from your source systems, which typically contains supplier duplications, inconsistent naming, missing categories and coding errors, and producing a clean, structured dataset. This involves deduplication, supplier normalization, categorization and enrichment with additional context.
For most organizations, initial spend data cleansing and categorization can be completed within two to four weeks, depending on data volume, the number of source systems and the condition of the incoming data. SpendQube will give you a clear timeline at the outset based on your specific situation.
Our procurement specialists review spend that cannot be classified with confidence by automated processing. This human review layer is what ensures high categorization coverage rates, particularly for complex, indirect or unusual spend types.
This is a common scenario. SpendQube is built to ingest and reconcile data from multiple source systems simultaneously. Different formats, currencies and coding conventions are normalized as part of the consolidation process.
SpendQube supports both. An initial cleansing engagement delivers your first clean dataset. From there, the platform can be configured to process new spend data on a regular basis: monthly, quarterly or in line with your reporting cycle, so data quality is maintained over time.
Categorization accuracy depends on the quality and completeness of the incoming data, but SpendQube typically achieves high coverage rates across spend. We are transparent about categorization confidence levels and flag areas where additional context would improve accuracy.

Instant insight. Trusted data. Complete control.
